Перебор паролей: как профиль пользователя превращается в словарь
21 ноября, 2025, Oleg AfoninРубрика: «Безопасность», «Криптография и шифрование», «Полезные советы», «Программное обеспечение»
Подавляющее большинство паролей — особенно таких, которые приходится вводить вручную, — как правило, не случайны. В состав паролей входят имена и фамилии, клички животных, части памятных дат, цифры из телефонных номеров и другие данные, которые можно охарактеризовать словом «персональные». В ряде случаев всё, что есть у специалиста — это зашифрованный диск или файл. Однако в реальной практике бывает доступен и профиль подозреваемого — набор данных, который, если его правильно обработать, превращается в структурированный инструмент для построения целевых атак.
В этой статье мы рассмотрим, как именно данные из дела преобразуются в целевой словарь способом, который требует только базовых аналитических навыков и опыта работы с зашифрованными данными. Мы попытаемся не просто перечислить этапы или выдать общие рекомендации, а показать, как формировать словарь так, чтобы разные специалисты могли прийти к сопоставимым результатам.
Посмотреть и подумать?
Самый распространённый совет, который даётся практически во всех криминалистических руководствах по восстановлению паролей — «посмотреть и подумать». И если с «посмотреть» проблемы, как правило, не возникает, то что означает «подумать»? В какую сторону «думать», как именно, что должно получиться в результате, а главное — как сделать так, чтобы этот результат получался как минимум похожим, если «смотреть и думать» будет два разных человека? Или другой совет, чуть более предметный: собрать как можно больше данных о подозреваемом и «использовать» их для составления целевого, персонализированного словаря. Совет прекрасный, но как именно — «использовать»? Просто сохранить файл со всеми именами и датами и запустить по нему атаку с мутациями по умолчанию? Этот момент, как правило, подробно разбирается во время профессионального обучения, тренингов и курсов повышения квалификации, но открытых материалов на эту тему в сети до обидного мало.
Проблема здесь в отсутствии формальной методики: профиль есть почти всегда, но точный путь от профиля к словарю обычно остаётся за скобками. Попробуем исправить это упущение.
Откуда брать данные для профиля?
Разнообразную персональную информацию можно собирать как непосредственно из материалов дела, так и из других источников — аккаунтов в социальных сетях, доступной переписки, наконец — из различных устройств и облачных сервисов подозреваемого. При сборе данных стоит фиксировать и контекст: в какой среде использовалось имя или дата, насколько часто оно встречается, в каком написании оно записано; эти информация поможет правильно расставить приоритеты.
Какие данные нужны для словаря?
Не вся информация из материалов дела одинаково полезна; есть более важные и менее важные моменты. В первую очередь стоит обращать внимание на:
- имена и фамилии подозреваемого, членов его семьи и окружения, включая уменьшительно-ласкательные версии (их придётся добавлять вручную)
- клички, никнеймы, прозвища
- даты — дни рождения, памятные даты (они войдут в словарь в качестве полноправных токенов с высоким приоритетом; все другие даты можно будет добавлять в виде суффиксов и мутаций)
- возможно, другие данные; какие именно, можно узнать, просмотрев (если доступны) известные пароли того же пользователя
После сбора данных стоит ранжировать их по уровню важности. Например, дата рождения самого пользователя всегда будет иметь более высокий приоритет, чем дата рождения двоюродного брата, а основной никнейм — выше, чем редкое игровое имя из одного конкретного сервиса (которое, возможно, и вовсе было сгенерировано случайным образом или выбрано по принципу «лучшее из всё ещё доступного»).
Токены
Разумеется, информацию из профиля нельзя просто включить в словарь в сыром, необработанном виде. Персональные данные необходимо конвертировать в токены — нормализованные слова и части слов. Как правило, в процессе нормализации все слова преобразуются в нижний регистр; из них удаляются все знаки препинания и специальные символы, а разделённые ими части сохраняются в виде раздельных токенов (пример: известны логины пользователя «alex.ivanov» и «alex_ivanov»; оба преобразуются в два токена: «alex» и «ivanov»).
Токен — это минимальная самостоятельная единица, которая может входить в пароль: слово, фрагмент слова, число, дата или их нормализованный вариант.
У русского языка (а точнее — кириллицы) есть дополнительная специфика, разобраться с которой вам поможет только опыт. Насколько часто вам в вашей практике встречались пароли, включающие символы кириллицы? Возможно, вместе с транслитерированными вариантами стоит добавлять в словарь и токены в их оригинальном написании. Не забывайте о различных вариантах транслитерации; как правило, какой-то один вариант для конкретного пользователя является предпочтительным (это можно выяснить, просмотрев имена логинов и псевдонимы пользователя).
Например:
- Александр: александр, alexander, alexandr, aleksandr
- Андрей: андрей, andrey, andrei
- Михаил: михаил, mikhail, mihail
Не забывайте сокращённые и уменьшительно-ласкательные варианты имён, сокращения, усечения, обрезанные формы (например, «sasha», «san», «sha»); каждый из вариантов написания станет отдельным токеном. Практическую полезность такого подхода поможет оценить список известных логинов, псевдонимов и, возможно, известных паролей пользователя, а также — ваш личный опыт. Дополнительно стоит учитывать смешанные варианты: часть слова на кириллице, часть — латиницей, поскольку такие комбинации нередко встречаются при смене раскладки.
Не забывайте о валидации токенов: имеет смысл исключать слишком длинные строки, технические идентификаторы, явно случайные вхождения, а также данные, не характерные для реальных паролей.
Помимо персональных данных в словарь можно включить и токены, часто встречающиеся в паролях именно в вашей местности. Важно помнить, что практическая ценность утечек в десятки и сотни миллионов паролей — крайне низкая. Пароли — локальны; как составные части (токены), так и способы формирования паролей сильно зависят от местных условий, поэтому понять, какие именно дополнительные слова стоит, а какие — не стоит включать в целевой словарь вам поможет только личный опыт.
Итак, мы составили профиль пользователя и разбили его на отдельные токены, составив из них целевой словарь. Что дальше?
Шаблоны
Следующий шаг — на основе словаря с токенами (зададим файлу имя custom_dict.udic) создать атаку с использованием шаблонов или масок. Проще всего задать маски окончания и/или приставки. В этом случае к каждому слову из целевого словаря будет добавляться окончание и/или приставка, сформированная согласно правилам. Например, в Elcomsoft Distributed Password Recovery правило «?d(0-99)» добавит число от 0 до 99 включительно; полный список правил описан в документации продукта.
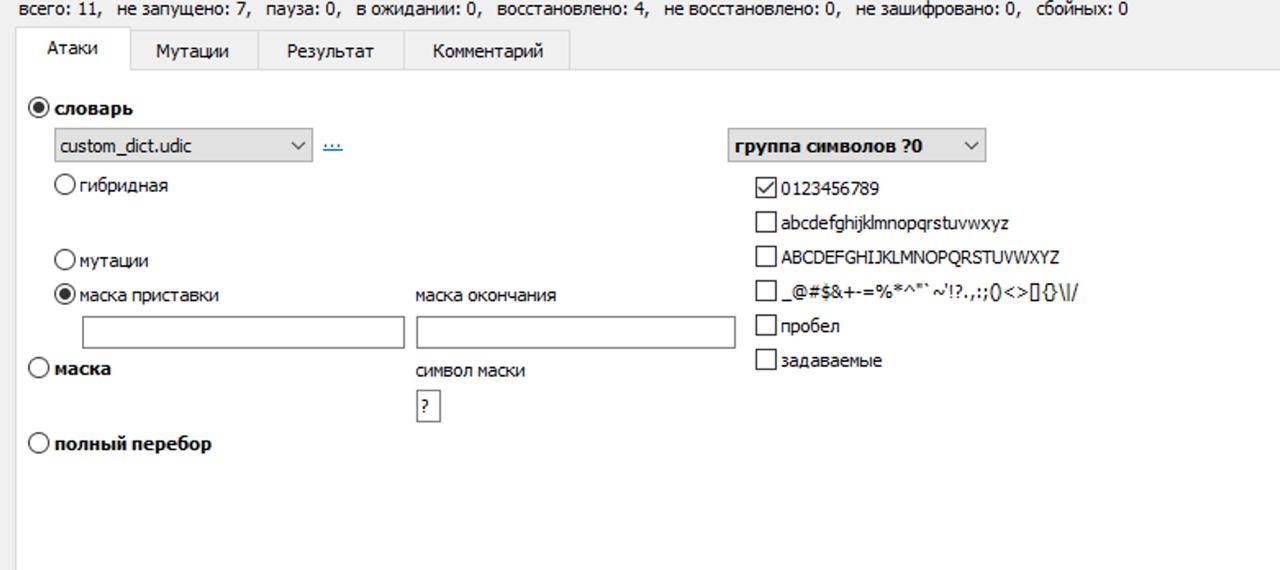
Какие правила имеет смысл использовать? В первую очередь это зависит от уже известных данных (например, если пользователь использовал в качестве логина «alex12», то используется маска окончания, добавляющая одну или две цифры в конец слова. В целом для русскоязычных пользователей особенно характерны: заглавная первая буква, добавление одной-двух цифр в конце, добавление «!» или «?» в конце, а также сочетания «ФамилияГод» («Ivanov1988», «ivanov88») или «имяГод» («alex1988», «alex88»).
А что делать, если, к примеру, нужно проверить пароли, начинающиеся с заглавной буквы или целиком написанные в верхнем регистре? В этом случае на помощь приходят мутации.
Мутации
Мутации в контексте перебора паролей — это набор полуавтоматических шаблонов и правил, которые превращают токены из словаря в полноценные пароли для проверки. Важно выбирать только те типы мутаций, которые реально могли быть использованы конкретным человеком; логика здесь та же, что и при выборе шаблонов.
Важно понимать различие: маски задают структуру будущего пароля (например, имя + две цифры), а мутации помимо этого могут изменять и сам токен (например, делая первую букву заглавной). Маски работают проще, они более предсказуемы, если можно предположить структуру пароля: «слово + год», «слово + ! или ?», «слово + 123» и т.д.
Мутации определяют, как токены превращаются в варианты паролей. Имея нормализованный набор токенов, можно применять различные преобразования, отражающие типичные поведенческие привычки как широкого круга пользователей, так и конкретного подозреваемого. Обычно люди используют одни и те же приёмы: делают первую букву заглавной, добавляют цифры, ставят символы в конце, заменяют буквы на похожие знаки. Систематическое применение таких правил позволяет расширить небольшой набор персонализированных токенов до миллионов реалистичных комбинаций, при этом не расходуя ограниченные вычислительные ресурсы впустую.
Для русскоязычных пользователей характерны свои паттерны: заглавная буква в начале встречается намного чаще, чем написание всего слова в верхнем регистре; сочетания вида «слово!» используются чаще, чем сложные символы; замены по «хакерским» правилам l33t встречаются значительно реже, чем в англоязычной среде.
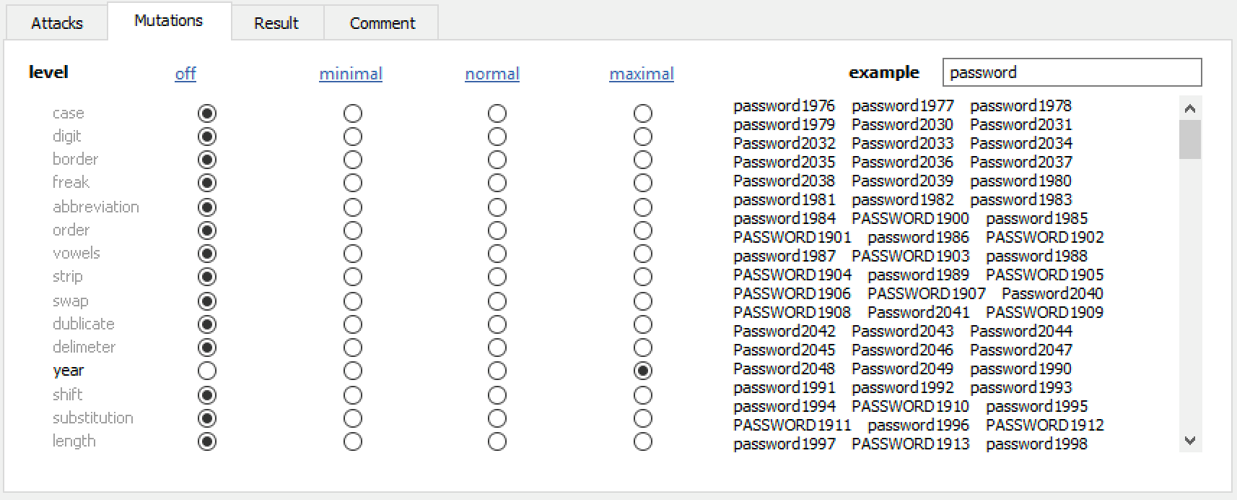
Мутации представлены группами правил. Изменения регистра превращают «alex» в «Alex» или «ALEX». Цифровые мутации добавляют числа, например, год рождения «alex91» или (если степень мутации повысить до максимальной) «Alex91», «ALEX91». Мутации «год» автоматически подставляют четыре цифры года. Эти правила можно комбинировать — люди часто наслаивают несколько изменений сразу. Но выбирать их нужно с учётом временных затрат и имеющихся вычислительных мощностей: чем больше мутаций задействовано и чем выше их степень, тем быстрее (экспоненциально) растёт объём проверяемых вариантов. Использование более трёх мутаций в «обычном» режиме или более двух — в «максимальном», как правило, нецелесообразно; единственное исключение — когда точно известно, что пользователь именно таким способом создаёт свои пароли.
При использовании мутаций не забывайте фиксировать, какие именно правила были использованы и в какой последовательности — это обеспечивает воспроизводимость атаки и избавит вас от повторного запуска одних и тех же атак.
Главное — сохранить баланс между полнотой перебора и временем, которое будет на него затрачено. Каждая группа мутаций расширяет пространство поиска, но чрезмерное количество правил только замедлит процесс, не повышая вероятность успеха. Специалист должен определить, какие преобразования характерны для конкретного пользователя, и какие комбинации оправданы с точки зрения вычислительных затрат. Цель — не перебрать все возможные варианты, а сгенерировать именно те, которые человек с высокой вероятностью мог использовать.
Заключение
Грамотно выстроенная целевая атака опирается не на объём, а на точность. Вместо миллионов случайных комбинаций специалист использует структурированный набор токенов, шаблонов и мутаций, отражающих реальные привычки конкретного человека или группы людей. Такой подход позволяет резко сократить время перебора и повысить вероятность успешного восстановления пароля на ранних этапах. В отличие от типовых рекомендаций «посмотреть и подумать», предлагаемая нами методика в достаточной степени воспроизводима: от сбора и нормализации пользовательских данных до создания токенов, построения шаблонов и выбора оптимальных мутаций.
При аккуратном применении этот процесс превращает разрозненные сведения из материалов дела в практический инструмент цифровой криминалистики. Итогом становится компактный набор токенов, из которых составляется целевой словарь, учитывающий личные предпочтения пользователя и реальные закономерности. Такой словарь остаётся прозрачным, понятным и пригодным для последовательного расширения и дальнейшей адаптации.
REFERENCES:
Elcomsoft Distributed Password Recovery
Производительное решение для восстановление паролей к десяткам форматов файлов, документов, ключей и сертификатов. Аппаратное ускорение с использованием потребительских видеокарт и лёгкое масштабирование до 10,000 рабочих станций делают решение Элкомсофт оптимальным для исследовательских лабораторий и государственных агентств.
Официальная страница Elcomsoft Distributed Password Recovery »



- iOS Forensic Toolkit 8.70: поддержка всех версий Apple Watch и офлайновая установка агента-экстрактора15 May, 2025
- Elcomsoft System Recovery 8.34: высокая скорость снятия образов и масса новых возможностей 29 April, 2025
- Быстрый просмотр событий Windows в Elcomsoft System Recovery 19 December, 2024
- iOS Forensic Toolkit 8.62: работа над ошибками22 November, 2024
- Elcomsoft Distributed Password Recovery получил функцию балансировки нагрузки14 November, 2024