NVIDIA Blackwell: новое поколение GPU может удвоить скорость перебора паролей (но это не точно)
27 февраля, 2025, Oleg AfoninРубрика: «Разное»
Специалисты давно используют видеокарты для перебора паролей в рамках расследований. GPU отлично справляются с этой задачей благодаря тысячам параллельных потоков, позволяя быстро — в сотни раз быстрее, чем на центральном процессоре, — вычислять хэши. В специализированных инструментах, таких как Elcomsoft Distributed Password Recovery, видеокарты обеспечивают многократное ускорение по сравнению с традиционными CPU. В новой архитектуре NVIDIA Blackwell число целочисленных вычислительных блоков, наконец, сравнялось с числом процессоров, работающих с плавающей точкой. В теории это может удвоить скорость некоторых вычислений; на практике прирост производительности может оказаться скромнее.
Blackwell: новые возможности
Недавно представленные видеокарты NVIDIA серии GeForce RTX 50 (архитектура Blackwell) получили сравнительно небольшие изменения по сравнению с поколением Ada Lovelace, которое они заменяют. Чипы по-прежнему производятся по старому техпроцессу, а число исполнительных блоков существенно выросло только на флагманской модели RTX 5090, которую в настоящий момент практически невозможно найти в продаже даже за ту высокую цену, которую просят производители.
В то же время с выходом архитектуры Blackwell произошло малозаметное, но важное событие: NVIDIA заявила об удвоении операций целочисленных вычислений (INT32) на такт по сравнению с предыдущей архитектурой Ada Lovelace. В теории это удвоение может дать прирост производительности в задачах, связанных с генерацией адресов и прочих, требующих целочисленной арифметики. Возможно, существенный прирост смогут получить и некоторые алгоритмы вычисления хэш-функций; впрочем, это потребуется проверять на практике.
За счёт чего при минимальном изменении архитектуры и старом техпроцессе произошло удвоение целочисленной производительности?
В документе (PDF), описывающем новую архитектуру, появилась информация о том, что Blackwell произошли важные изменения. С учётом растущего использования ИИ и необходимости быстрых целочисленных вычислений для подобных нагрузок, все шейдерные ядра теперь могут выполнять как целочисленные инструкции INT32, так и вычисления с плавающей точкой FP32. В поколении Ampere (RTX 30) половина только половина из всех имеющихся ядер могла выполнять инструкции INT32/FP32, тогда как другая половина поддерживала только вычисления с плавающей точкой. Ada Lovelace (RTX 40) сохранила эту схему, а в Blackwell все ядра CUDA стали унифицированными. Фактически, NVIDIA вернулась к схеме времён Turing (RTX 20), исполненной на качественно новом уровне.
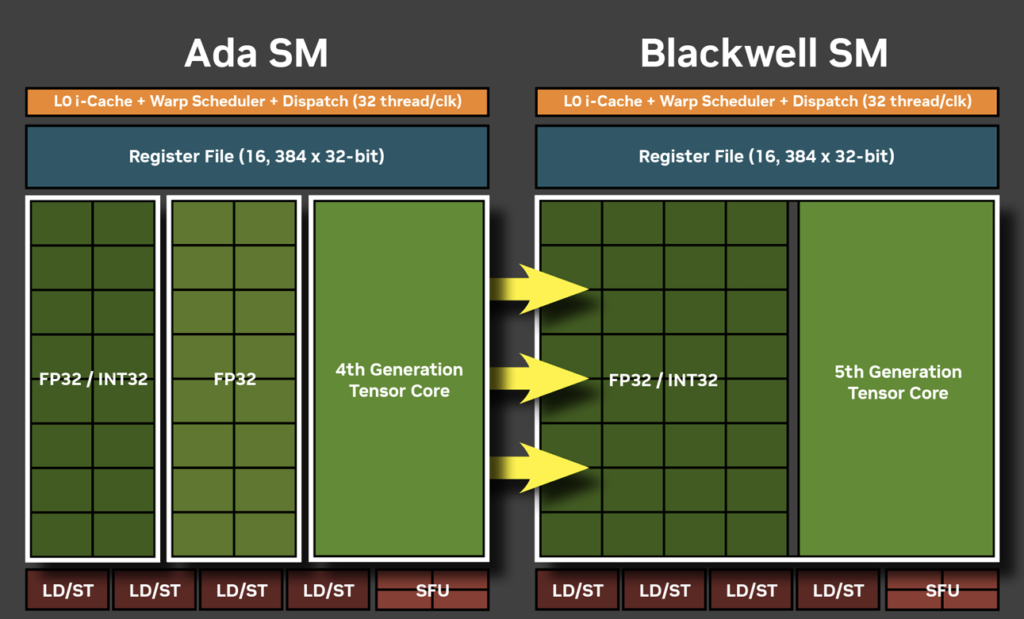 Теория vs. практика
Теория vs. практика
В теории удвоение числа вычислительных блоков INT32 должно привести к удвоению скорости целочисленных вычислений, однако на практике этого не произошло: практические тесты пока не подтверждают ожидаемый двукратный рост скорости. Как отмечают энтузиасты, ни в тестах, ни в практических задачах новые видеокарты не показывают значительного прироста в производительности целочисленных операций. Возможно, улучшения касаются лишь специфических сценариев, таких как neural shading, а не всех целочисленных вычислений в целом. Так, разработчики hashcat, продукта для перебора паролей с открытым исходным кодом, отмечают ускорение на RXT 5090 порядка 20% относительно скорости 4090 — что даже меньше 33% увеличения числа вычислительных блоков CUDA в новом флагмане (RTX 5090 оборудован 21,760 ядрами CUDA, а в RTX 4090 их 16,384).
Так стоит ли обновляться?
Запуск нового поколения видеокарт не был для NVIDIA ни простым, ни гладким. У компании были производственные проблемы, которые привели к дефициту чипов и в результате — недостаточному количеству выпущенных на момент анонса видеокарт. Дефицит видеокарт на старте продаж, в свою очередь, привёл к нездоровому ажиотажу, дефициту и спекуляциям. Вызывают вопросы и надёжность коннекторов на флагманской модели, и стабильность работы новых видеокарт с шиной PCIe5.0, и случайные отключения экрана компьютера; не оптимизированы и не избавлены от ошибок и ранние версии драйверов. Наконец, некоторым покупателям достались бракованные экземпляры с частично отключенными блоками рендеринга.
Приобретать карты нового поколения «здесь и сейчас» нет смысла, если речь идёт о переборе паролей. Поддержка новой архитектуры в Elcomsoft Distributed Password Recovery — в разработке; если вы установите новую видеокарту до того, как мы обновим EDPR, то перебор паролей на ней просто не заработает. Рекомендуем дождаться анонса о выходе новой версии в нашем блоге; мы собираемся подробно протестировать новую архитектуру на наших задачах.
Неоднозначной остаётся и ситуация с обновлением карт предыдущего поколения: если обновить аппаратную часть с карт Ampere (30-я серия) может иметь смысл, то обновлять ускорители на Ada Lovelace (40-я серия) точно не стоит: дополнительные затраты не окупятся с точки зрения полученной производительности.
В следующей таблице мы сравнили ключевые характеристики двух флагманов: RTX 4090 и RTX 5090.
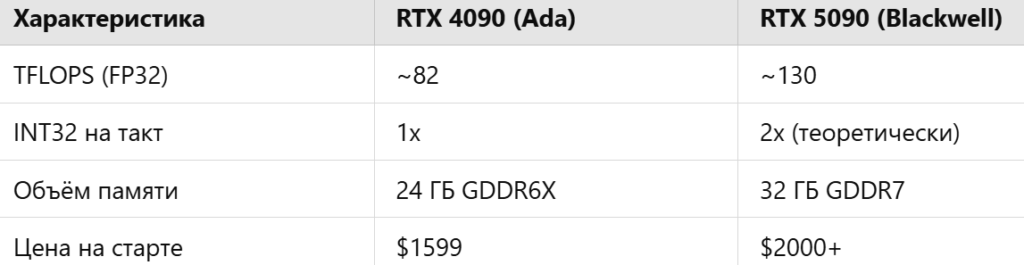
Хотя новая линейка действительно мощнее в теории (а флагман — и на практике, из-за намного большего числа вычислительных блоков и существенно более высокого энергопотребления), её эффективность в задачах перебора паролей пока под вопросом. Даже офицальный рост стоимости карт на 30-50% делает их менее привлекательными с точки зрения соотношения цена/производительность — при том, что найти в продаже флагманские карты RTX 5090 и 5080 по рекомендованным производителями ценам практически невозможно.



{kind=link}
{kind=link}
- iOS Forensic Toolkit 8.70: поддержка всех версий Apple Watch и офлайновая установка агента-экстрактора15 May, 2025
- Elcomsoft System Recovery 8.34: высокая скорость снятия образов и масса новых возможностей 29 April, 2025
- Быстрый просмотр событий Windows в Elcomsoft System Recovery 19 December, 2024
- iOS Forensic Toolkit 8.62: работа над ошибками22 November, 2024
- Elcomsoft Distributed Password Recovery получил функцию балансировки нагрузки14 November, 2024