Искусственный интеллект в криминалистике
3 октября, 2025, Oleg AfoninРубрика: «Разное»
Искусственный интеллект — устойчивый тренд последних лет. Машинное обучение внедряют буквально везде — от холодильников до пакетов для разработки ПО. Не обошла мода на машинное обучение и продукты для цифровой криминалистики: модели искусственного интеллекта позиционируются как помощь в обработке больших массивов разнородных данных. Насколько в принципе допустимо использование машинного обучения в криминалистике и где прочерчены красные линии? Попробуем разобраться.
Искусственный интеллект — не замена здравому смыслу
Крупные вендоры относятся к машинному обучению с осторожностью. С одной стороны, искусственный интеллект — прекрасная реклама. С другой — разработчики хорошо понимают ограничения таких моделей: «галлюцинации», когда модель из-за недостатка информации просто «придумывает» ответ, «подгоняя» его под контекст; в случае с моделями для транскрибирования — ненадёжное распознавание и ошибки; ложные положительные и ложные отрицательные срабатывания моделей распознавания, призванных ускорить поиск нелегальных материалов среди бесчисленных фото и видео. Искусственный интеллект не может выступать в роли следователя; на его решения нельзя полагаться. Однако от него этого и не требуется.
Машинное обучение не призвано заменить живого эксперта; вместо этого искусственный интеллект может взять на себя рутинные задачи — поиск и фильтрацию данных по обычному текстовому запросу, поиск ключевых слов в аудио, опять же — распознавание визуальных объектов и поиск нелегальных изображений. Если в каждом сеансе общения с искусственным интеллектом модель приводит ссылки на источники (а именно так и должны поступать специально обученные модели, использующиеся в криминалистических пакетах), то следователь может сделать собственные выводы на основе исходных данных.
И здесь возникает основная проблема: человеческий фактор. Слишком велик соблазн использовать готовый, связный и красиво оформленный вывод, сделанный моделью искусственного интеллекта, проведя в лучшем случае поверхностную проверку. Конечно же, так делать нельзя. А как — можно?
Обработка больших массивов данных
Объёмы данных, а следовательно — и цифровых улик, постоянно растут. Растут не только объёмы данных, но и их разнообразие. Голосовые сообщения, фото и видео занимают десятки и сотни гигабайт данных, обработка которых вручную может оказаться чрезмерной и практически невыполнимой задачей в реальных условиях.
И здесь на помощь приходит искусственный интеллект. Он способен эффективно искать нужные и отфильтровывать ненужные данные, практически моментально делать информационную выжимку из длинных, малоосмысленных чатов и переписок, и даже понимать разные языки и сленговые выражения — разумеется, в рамках сложности самой модели.
Например, в продукте Belkasoft Evidence Center встроенный ассистент на основе ИИ позволяет разбирать массу медиа-файлов и делать выжимки текстов, полученных из различных источников. Более сложные модели способны самостоятельно отмечать данные, требующие более пристального внимания.
Даже простые текстовые данные могут включать элементы форматирования и иконки эмодзи, которые способны кардинально изменить весь смысл сообщения — и это не выдумка: ещё в 2023 году канадский суд признал эмодзи «большой палец вверх» эквивалентом цифровой подписи на контракте. Подобные вещи однозначно не должны интерпретироваться моделями искусственного интеллекта; любые решения и интерпретации остаются прерогативой человека.
Не текстом единым
Артефакты — это не только и не столько текст, сколько различные медиафайлы. Современные модели ИИ довольно неплохо справляются с сортировкой и классификацией изображений и видео (хотя и ошибаются в обе стороны; у них хорошо получается идентифицировать лица и осуществлять поиск по ним среди массы фотографий (и здесь также нужно учитывать ошибки в обе стороны). Искусственный интеллект может «подсветить» потенциально инкриминирующие файлы и отбросить заведомо неинтересные, позволив человеку не просто сэкономить время, а использовать доступные ограниченные ресурсы с максимальной эффективностью.
То же относится и к аудиозаписям. В большинстве современных мессенджеров есть функция «голосовых сообщений», которая пользуется заметной популярностью. У современных моделей искусственного интеллекта хорошо получается транскрибировать такие записи — но и здесь им нельзя доверять полностью: нюансы, акценты, интонации и сленговые выражения остаются за пределами возможностей искусственного интеллекта. Однако помочь человеку понять, на какие сообщения стоит обратить внимание, а на каких можно сэкономить время — ничуть не менее важно.
Вопрос доверия
Если ИИ постоянно ошибается, а то и откровенно «додумывает» информацию, можно ли ему доверять? Разумеется, нет! Об этом сразу предупреждают и разработчики криминалистических пакетов. Да, языковые модели не понимают подтекст и намёки. Да, они совершенно не воспримут интонации и сленговые выражения, распространённые среди узких сообществ. Модель никогда не сможет корректно определить намерение. Наконец, если задать модели один и тот же вопрос несколько раз подряд — вы получите несколько разных ответов, различия между которыми могут быть как незначительными (порядок слов, выбор выражений), так и существенными.
Что с этим можно сделать? Разработчики постоянно совершенствуют алгоритмы, стараясь уменьшить недетерминированность моделей, но этого недостаточно: важно не только давать максимально точные ответы, но и приводить исходные данные, на которых эти ответы основаны. Модель «BelkaGPT» разработки компании Belkasoft пытается работать именно таким образом: в своих ответах модель приводит отсылки на исходные данные, на основе которых ИИ выдал тот или иной ответ.
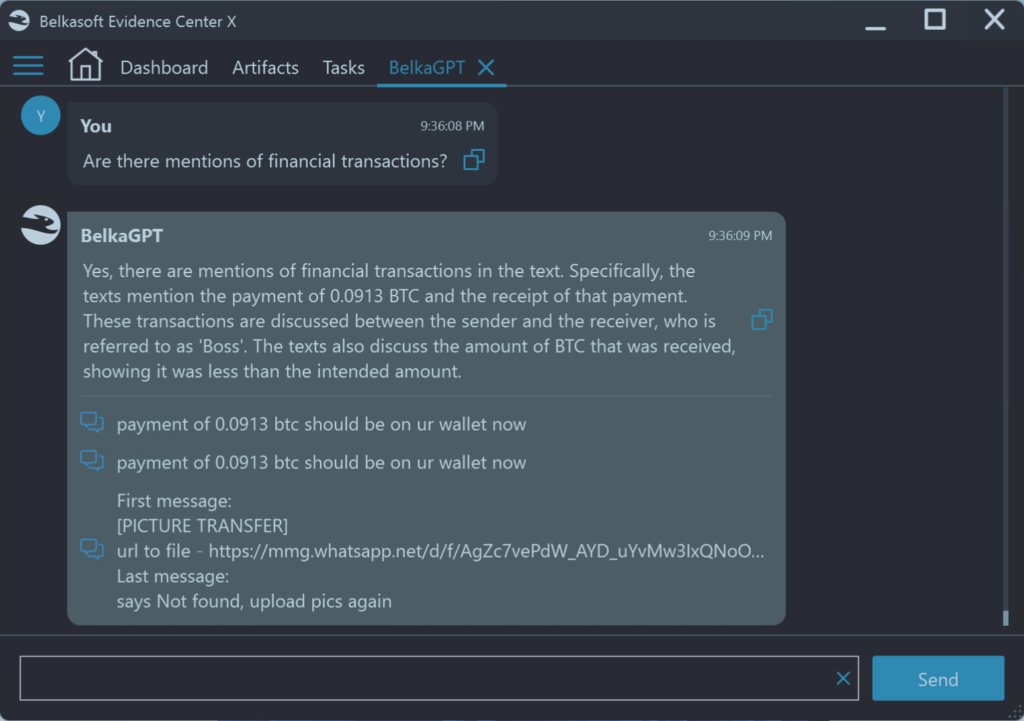
ИИ в цифровой криминалистике стоит рассматривать как секретаря — быстрого, но неаккуратного. Да, он может быть полезен, может сэкономить массу времени, но полагаться на его слова нельзя. Во фразе «искусственный интеллект» акцент — на слове «искусственный». Машина не способна заменить человеческое мышление. Любые оценки и выводы всегда остаются за экспертом, и именно он несёт за них полную ответственность.
Как можно и как нельзя использовать машинное обучение
«Искусственный интеллект» — это звучит красиво, но в суде аргумент «так сказал компьютер» — довольно слабый. ИИ ошибаются, иногда незначительно, иногда — катастрофически. Если данных мало или они плохого качества, ИИ и вовсе может «додумать недостающее». Ошибки имеют свойство накапливаться, и конечный результат может иметь мало общего с исходными данными.
В этом — вторая опасность: несмотря на ошибки и галлюцинации, выводы искусственного интеллекта всегда красиво оформлены и убедительно выглядят. Соблазн просто взять и принять предложенный моделью результат за чистую монету, ограничившись поверхностной сверкой с исходными данными, слишком велик. Но автоматическая система не несёт ответственности за свои выводы, а «ошибка по вине компьютера» — это всё равно ошибка, ответственность за которую будет нести эксперт. В российской судебной практике действует принцип допустимости доказательств: если эксперт не может объяснить происхождение и достоверность данных, суд их просто не примет.
Есть и правовые нюансы. Любое действие с цифровыми доказательствами должно соответствовать требованиям процессуальных норм. Если система выдала транскрипт, сводку или классификацию файлов, это уже производный артефакт, который необходимо отдельно документировать, фиксировать методику его получения и связывать с исходными данными. Без этого такие результаты могут быть полезны для оперативной работы, но вряд ли будут приняты в суде.
Вот лишь несколько правил, которые помогут избежать проблем:
- «Доверяй, но проверяй». На результаты, выданные моделью ИИ, можно ориентироваться, но на них нельзя полагаться. Обязательно сверяйте все выводы с исходными материалами.
- Фиксируйте процесс. Документируйте, какое ПО, какая версия и с какими настройками использовалась.
- Сохраняйте контекст. Не стоит рассчитывать, что алгоритм «поймёт» сленг, подтекст или скрытый смысл — это обязанность эксперта.
- Выводы — прерогатива эксперта. ИИ можно использовать для ускорения рутинных операций, но выводы всегда делает конкретный человек, который будет нести за них ответственность.
- Осторожнее с облачными моделями! Соблазн использовать более мощную и качественную модель из «облака» велик, но облачные сервисы невозможно контролировать; многие из них сохраняют все запросы, используя их для дальнейшего обучения модели. В ряде случаев это противоречит требованиям законодательства и конфиденциальности. Локальные решения могут не быть такими же «умными», как облачные модели, но информация гарантированно не покинет пределов вашей лаборатории.
- Соблюдайте процессуальные нормы. Каждый артефакт, созданный ИИ, должен быть привязан к исходным данным и оформлен так, чтобы его можно было предъявить в суде.
В каких продуктах используются модели ИИ?
На данный момент криминалистических пакетов со встроенными моделями искусственного интеллекта не так много. В пакете Magnet AXIOM модель «Magnet.AI» используется для классификации чатов и изображений по категориям. В Belkasoft Evidence Center ИИ используется для создания краткого содержания переписок, классификации изображений и транскрибирования аудио. Цифровые ассистенты здесь используются в качестве одного из вспомогательных инструментов; их производители явно предупреждают: искусственный интеллект — не замена здравому смыслу, но неплохое дополнение.



- iOS Forensic Toolkit 8.70: поддержка всех версий Apple Watch и офлайновая установка агента-экстрактора15 May, 2025
- Elcomsoft System Recovery 8.34: высокая скорость снятия образов и масса новых возможностей 29 April, 2025
- Быстрый просмотр событий Windows в Elcomsoft System Recovery 19 December, 2024
- iOS Forensic Toolkit 8.62: работа над ошибками22 November, 2024
- Elcomsoft Distributed Password Recovery получил функцию балансировки нагрузки14 November, 2024