Порядок имеет значение: как правильно организовать очередь восстановления паролей
1 марта, 2023, Oleg AfoninРубрика: «Разное»
В статье Такой неполный полный перебор мы обсудили достоинства и недостатки метода полного перебора паролей для доступа к зашифрованным данным, и пришли к выводу, что из всего множества методов восстановления паролей полный перебор — наименее эффективный. В то же время экспертам-криминалистам приходится регулярно использовать перебор, чтобы расшифровать защищённые паролем улики. В этой статье мы расскажем о создании наиболее эффективной очереди задач по восстановлению паролей.
Восстановление паролей: различные атаки и очередь задач
В Elcomsoft Distributed Password Recovery процесс восстановления паролей оформлен в виде очереди задач. Каждая задача описывает одну атаку на один файл. Таким образом, для того, чтобы на одном и том же файле опробовать разные типы атак, создаётся несколько отдельных задач. Аналогичным образом одну и ту же атаку можно применить к разным файлам, для чего также создаются отдельные задачи.
Если в распоряжении эксперта есть информация о пользователе, которому принадлежат файлы, к которым требуется подобрать пароль, а тем более, если есть доступ к другим паролям того же пользователя, оптимальной будет организация «умных» атак, учитывающих известную информацию о принципах создания паролей конкретным пользователем. Это могут быть как словари, так и маски, шаблоны или гибридные правила. В то же время часто бывает так, что эксперту ничего не известно не только о владельце файлов, но даже о том, принадлежат ли все предоставленные файлы одному и тому же пользователю. В этом случае приходится прибегать к так называемым «холодным» атакам — то есть, атакам по распространённым паролям, паролям, составленным из одних цифр, словарным атакам с использованием общеупотребимых слов английского и русского языков как с мутациями, так и в чистом виде, и под конец — полному перебору. В таких случаях отдельной большой проблемой становится вопрос о том, в каком порядке расположить атаки, чтобы максимально увеличить шанс успешного восстановления пароля и уменьшить время ожидания. С этой целью мы можем рекомендовать одну из нескольких стратегий.
Проиллюстрируем сказанное на примере.
Очередь 1: Файл #1 ------ Атака #1 ------ Атака #2 ------ Атака #3 Файл #2 ------ Атака #1 ------ Атака #2 ------ Атака #3 Файл #3 ------ Атака #1 ------ Атака #2 ------ Атака #3
В приведённой выше очереди задач мы видим атаки, в которых различные атаки последовательно применяются сначала к первому файлу, затем — ко второму и последующим в порядке очереди. При такой организации очереди задач файлы с наименее стойкой защитой (об этом мы расскажем далее по тексту) располагаются вверху очереди, а самые стойкие форматы, соответственно, внизу списка. Подытожим: в очереди первого типа задачи расположены в порядке возрастания стойкости защиты файлов.
Есть и другой способ организации очереди, в котором в первую очередь запускаются самые короткие и быстрые атаки:
Очередь 2: Файл #1 ------ Атака #1 Файл #2 ------ Атака #1 Файл #3 ------ Атака #1 Файл #1 ------ Атака #2 Файл #2 ------ Атака #2 Файл #3 ------ Атака #2 Файл #1 ------ Атака #3 Файл #2 ------ Атака #3 Файл #3 ------ Атака #3
К примеру, в качестве первой атаки может использоваться атака по короткому словарю, второй — полноценная словарная атака, и только в последнюю очередь будет выполняться атака методом полного перебора. Таким образом, в очереди второго типа задачи расположены в порядке возрастания времени, затрачиваемого на конкретную атаку.
Разумеется, принципы формирования очередей можно комбинировать, создав гибридный порядок задач. Рассмотрим конкретный пример: нужно создать очередь задач, состоящую из пяти различных атак, применяемых к двум файлам. Очередь первого типа будет выглядеть так:
Newdocument.docx ------ Атака по словарю top-10000 ------ Цифровые пароли (1-6 цифр) ------ Словарная атака с мутациями по словарю английского языка English.dic ------ Словарная атака с мутациями по словарю русского языка Russian.dic ------ Полный перебор (1-8 символов) Expenses.xlsx ------ Атака по словарю top-10000 ------ Цифровые пароли (1-6 цифр) ------ Словарная атака с мутациями по словарю английского языка English.dic ------ Словарная атака с мутациями по словарю русского языка Russian.dic ------ Полный перебор (1-8 символов)
Обратите внимание: в приведённом выше примере полный перебор может не закончиться никогда. 8 знаков из полного набора символов удастся перебрать только для исключительно нестойких форматов, к каковым ни .docx, ни .xlsx не относятся. В то же время полностью отказаться от таких атак мы не можем: далеко не все пароли составляются по каким-либо правилам, тем более — словарным. Ситуация выправляется, если самые длительные атаки — атаки методом полного перебора, — перенести в самый низ очереди:
Newdocument.docx ------ Атака по словарю top-10000 ------ Цифровые пароли (1-6 цифр) ------ Словарная атака с мутациями по словарю английского языка English.dic ------ Словарная атака с мутациями по словарю русского языка Russian.dic ------ Полный перебор (1-8 символов) Expenses.xlsx ------ Атака по словарю top-10000 ------ Цифровые пароли (1-6 цифр) ------ Словарная атака с мутациями по словарю английского языка English.dic ------ Словарная атака с мутациями по словарю русского языка Russian.dic ------ Полный перебор (1-8 символов) Newdocument.docx ------ Полный перебор (1-8 символов) Expenses.xlsx ------ Полный перебор (1-8 символов)
Перенос самых длительных по времени атак вниз очереди позволяет относительно быстро испробовать самые распространённые виды паролей на обоих документах, и лишь в случае неудачи перейти к длительному полному перебору.
Гибридная очередь — не всегда оптимальный вариант. Если скорость перебора для одного файла превышает скорость атаки на следующий на несколько порядков (в тысячу и более раз), то очередь первого типа может показать лучший результат. Если же все файлы защищены примерно одинаково, то очередь второго типа или гибридная очередь задач повысят шансы на успешное восстановление в разумный срок.
Как правильно организовать очередь
Какой вариант организации очереди следует использовать: первый, второй или гибридный? В статье Такой неполный полный перебор обсуждалась стратегия «низко висящего фрукта», в рамках которой приоритет отдаётся коротким атакам с известным (и приемлемым) временем окончания. Соответственно, в рамках этой стратегии самые короткие по времени атаки должны оказаться наверху очереди, в то время как длительные атаки получают низший приоритет и располагаются внизу очереди.
Нужно различать «короткие» атаки и высокую скорость перебора как следствие относительно слабой защиты конкретного файла или формата. К примеру, атака по списку наиболее распространённых паролей (словарь top-10000) отработает практически моментально на любом формате. Это — классический пример «короткой» атаки. В то же время формат NTLM, о котором подробно рассказано в статье Пароли первой очереди: учётные записи Windows, NTLM и DPAPI, почти в 50,000 раз менее стойкий в сравнении с «эталонным» форматом шифрования ZIP AES-256. Чтобы принять взвешенное решение об очерёдности атак, нужно сравнить стойкость разных форматов между собой. Для этого обратитесь к таблице:
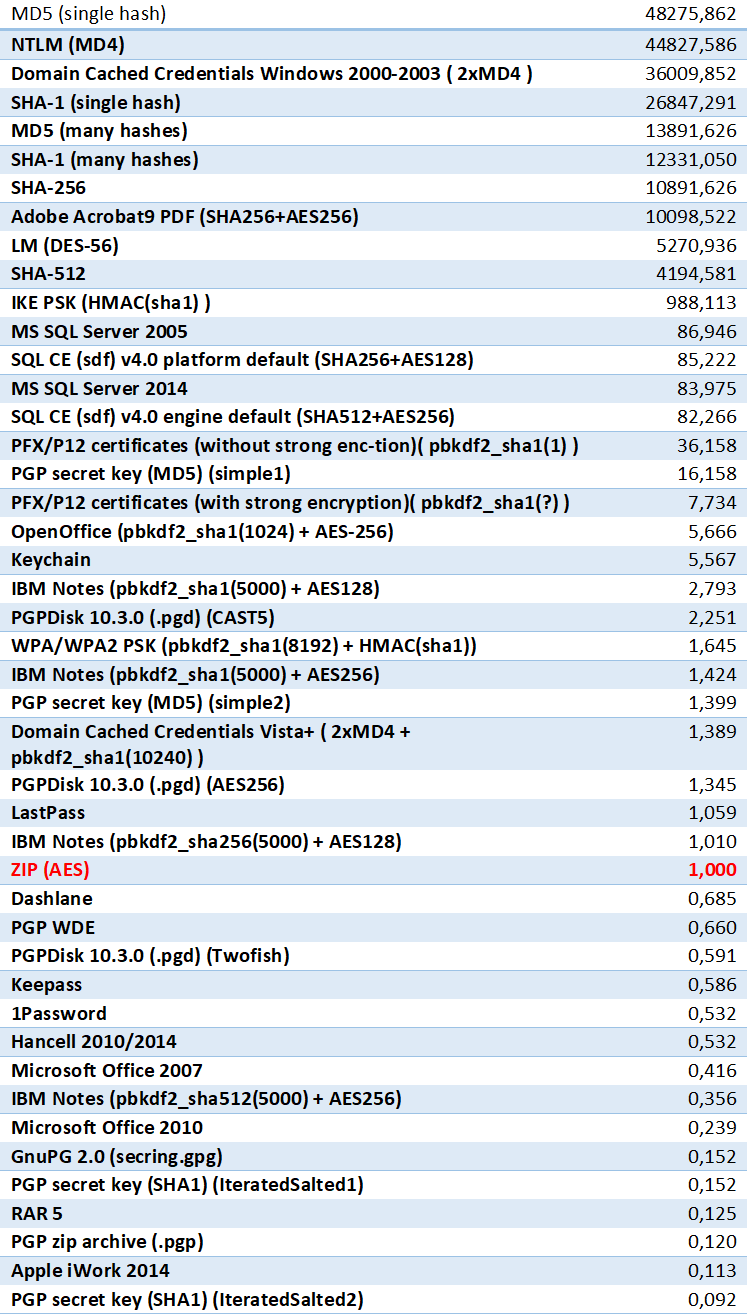
Из таблицы следует, что, к примеру, атака на пароли NTLM будет почти в 50,000 раз быстрее, чем атака на архив ZIP, защищённый шифром AES-256. Соответственно, атаку на пароли NTLM следует располагать в самом верху очереди, а саму очередь оформлять в первом варианте (с приоритетом наименее стойких форматов файлов). Формат документов Microsoft Office 2007, напротив, может быть атакован со скоростью вдвое ниже в сравнении с ZIP AES-256. Такая относительно небольшая разница не должна оказывать принципиального влияния на расположение файлов в очереди атак; соответственно, предпочтительным будет второй или гибридный вариант очереди.
Практические шаги
Итак, составим очередь задач в Elcomsoft Distributed Password Recovery.
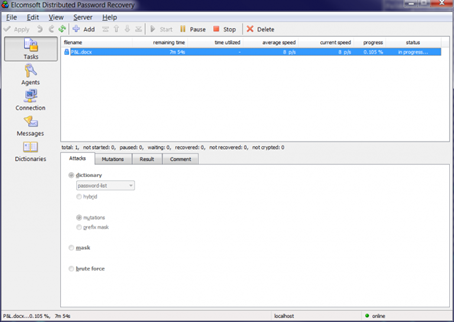
- В первую очередь настроим атаку по словарю top-10000 без мутаций:
- Далее добавим атаку цифровых паролей. Ограничим пространство возможных вариантов, указав максимальную длину пароля в 8 цифр (для более стойких форматов можно ограничиться шестью цифрами).
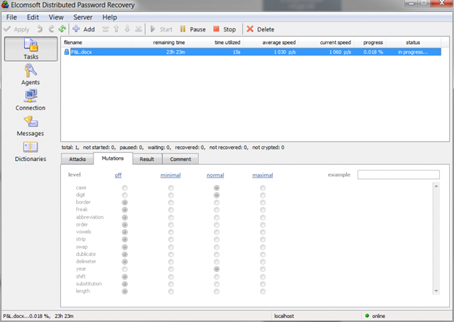
- Добавим ещё две атаки: по английскому и русскому словарям. Установим мутацию Year в среднее значение (normal). Для каждой из этих атак настройки будут выглядеть следующим образом:
- Наконец, в последнюю очередь настроим атаку методом полного перебора. Если вам известно что-либо о том, по каким принципам построены пароли, вы можете настроить соответствующие маски или гибридные правила. В противном случае перебор будет проходить по всему пространству паролей.
Заключение
Так же, как и в случае с мобильной криминалистикой, порядок имеет значение и при восстановлении доступа к зашифрованным уликам. Восстановление паролей работает по принципу очереди, состоящей из последовательных задач. Одна задача — это всегда одна атака на один файл. Если файлов несколько, очередь будет составлена из нескольких задач. Даже если файл, для которого нужно найти пароль, всего один, у вас всё равно будет очередь задач: с большой вероятностью вы захотите опробовать несколько различных атак, от самых быстрых и коротких (словарь из 10,000 распространённых паролей) до полного перебора. И в первом, и во втором случае порядок, в котором вы организуете задачи в очереди, имеет принципиальное значение. Правильно организованная очередь задач даст возможность найти максимальное количество паролей за минимальное время. Организованная неправильно очередь приведёт к неэффективным затратам машинного времени.
Выбор рабочего процесса зависит от того, как соотносится степень защиты файлов, которые необходимо взломать. Таблица, в которой мы сравниваем относительную стойкость различных форматов, поможет грамотно расставить приоритеты. В некоторых случаях большею эффективность покажут очереди, в которых файлы с самой слабой защитой помещаются в начало списка. В других приоритет отдаётся самым быстрым и коротким атакам на каждый файл, а длительные и трудоёмкие атаки размещаются в конце списка. Организация очереди атак всегда зависит от конкретного набора файлов, которые необходимо взломать, а также от относительной стойкости их защиты.
REFERENCES:
Elcomsoft Distributed Password Recovery
Производительное решение для восстановление паролей к десяткам форматов файлов, документов, ключей и сертификатов. Аппаратное ускорение с использованием потребительских видеокарт и лёгкое масштабирование до 10,000 рабочих станций делают решение Элкомсофт оптимальным для исследовательских лабораторий и государственных агентств.
Официальная страница Elcomsoft Distributed Password Recovery »

- iOS Forensic Toolkit 8.70: поддержка всех версий Apple Watch и офлайновая установка агента-экстрактора15 May, 2025
- Elcomsoft System Recovery 8.34: высокая скорость снятия образов и масса новых возможностей 29 April, 2025
- Быстрый просмотр событий Windows в Elcomsoft System Recovery 19 December, 2024
- iOS Forensic Toolkit 8.62: работа над ошибками22 November, 2024
- Elcomsoft Distributed Password Recovery получил функцию балансировки нагрузки14 November, 2024